A Modular 3D Face Reconstruction Benchmark: M3DFB paper presented in IEEE FG’25
Paper (arXiv) 📄 / Project Page 🌐 / Poster 📌 / Code 💻
Facial Basis paper (Beyond FACS) accepted and presented in IEEE FG’25
Project Page 🌐 / Poster 📌 / Code 💻
Our 3D reconstruction method (3DI) was published in TPAMI
3DI was published on Feb’24 issue of T-PAMI: https://ieeexplore.ieee.org/abstract/document/10330115 This paper shows how to implement the 3DI method efficiently, and provides experiments that show the ability of 3DI to capture person-specific facial morphology. Further, experiments show that 3DI stands out with its reconstruction performance that becomes increasingly more accurate as more frames per person are provided, whereas the performance of the compared deep learning-based methods tend to saturate earlier, with fewer number of frames.
On the Attention Mechanism
What is revolutionary about the attention mechanism is that it allows to dynamically change the weight of a piece of information. This is not possible with, say, traditional RNNs or LSTMs. Attention mechanisms were proposed for sequence-to-sequence translation, where they made a significant difference by allowing networks to identify which words are more relevant with the $t$th word in the translation (i.e., soft alignment), and putting more weight to them even if they are far apart from the word that is…
LSTM Examples #1: Basic Time Series Prediction
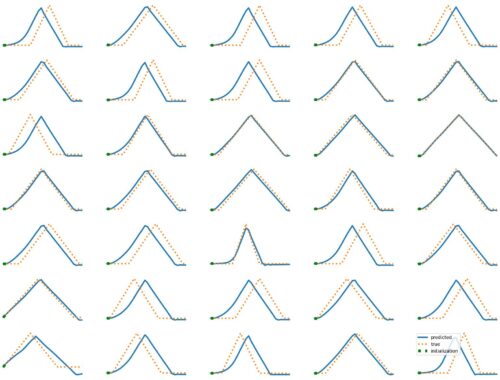
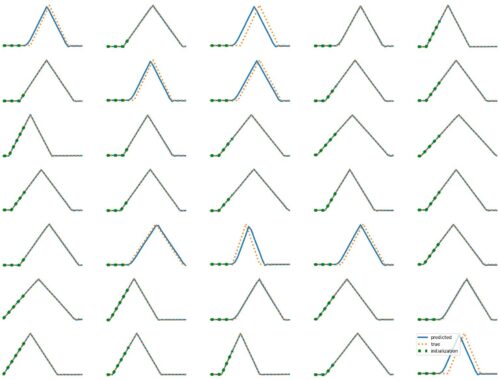
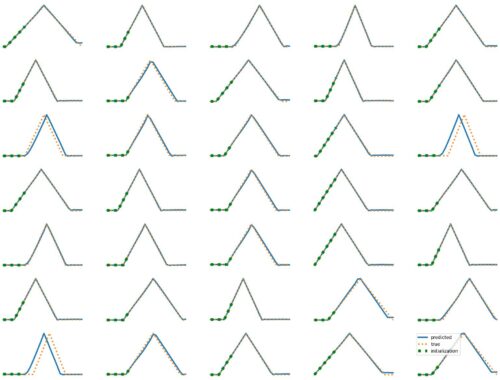

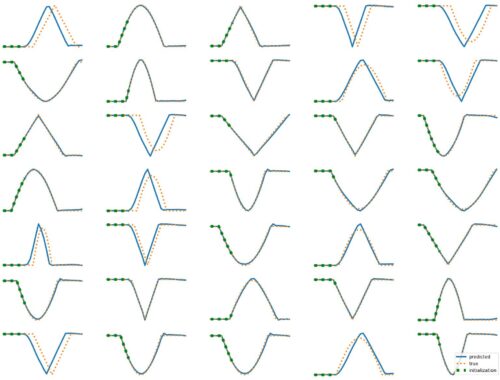

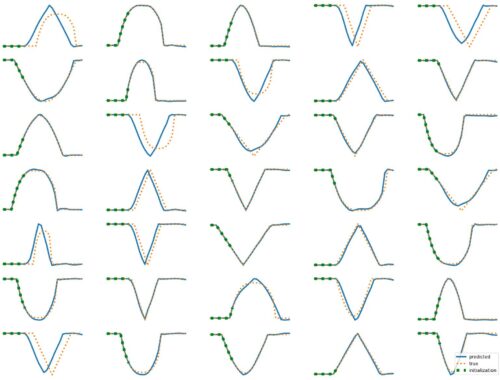


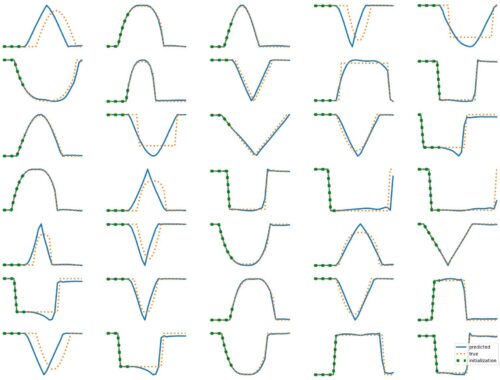
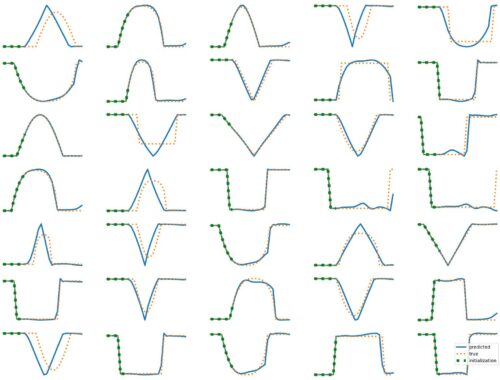
The results above illustrate how LSTM works with continuous input/output on simple 1D time series prediction tasks. We aim to estimate simple shapes by using past data. We follow an increasingly more complex scenarios. Results show the limitations of continuous time-series prediction via LSTM; the last slides show that even simple shapes cannot be accurately predicted. But the code is helpful to illustrate the basics of time-series prediction. Below we provide all the commands and the python script needed to generate…
Self-supervision on Deep Nets
Arguably, the main reason that deep nets became so powerful is self-supervision. In many domains, from image, to text, to DNA analysis, the concept of self-supervision was sufficient to generate practically infinite “labelled” data for training deep models. The idea is simple yet extremely powerful: just hide some parts of the (unlabelled) data and turn the hidden parts into the labels to predict. Here are some notes (mostly to myself) about self-supervision. There are two standard ways to make self supervision:…
State of the art in 3D face reconstruction may be wrong
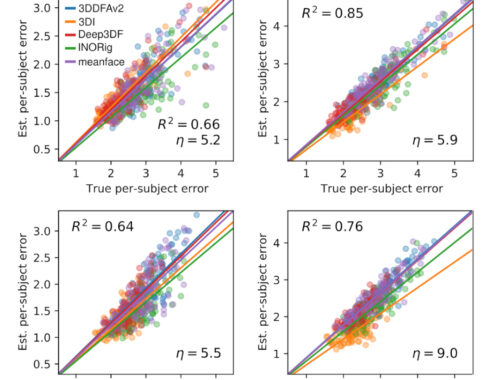
Our IJCB’23 study exposed a significant problem with the benchmark procedures of 3D face reconstruction — something that should make any researcher in the field worry. That is, we showed that the standard metric for evaluating 3D face reconstruction methods, namely geometric error via Chamfer (i.e., nearest-neighbor) correspondence, is highly problematic. Results showed that the Chamfer error does not only significantly underestimate the true error, but it does so inconsistently across reconstruction methods, thus the ranking between methods can be artificially…
Our paper on limitations of 3D reconstruction *benchmark metrics* was presented at IJCB’23
Our paper titled Meta-evaluation for 3D Face Reconstruction Via Synthetic Data was presented in an oral and also a poster presentation session of IJCB: https://ijcb2023.ieee-biometrics.org/oral-presentations/ Here is my blog post with the paper link and a summary of the study.
Some datasets for simple probability exercises
Some datasets with large $N$ that can be used for simple and interesting exercises: See also below for convenience
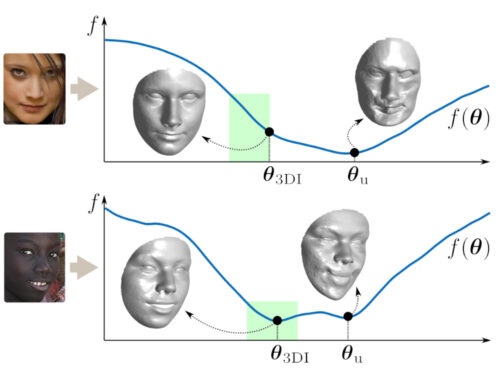
3DI: Face Reconstruction via Inequality Constraints
We present the CUDA code of our optimization-based 3DMM fitting method (i.e., no learning), which was first presented in ECCV’20. The journal version of the paper (currently under revision) presented a significant speed up with a new optimization approach, making the method feasible for real-life applications. 3DI is an optimization-based 3DMM fitting (3D reconstruction) method that enforces inequality constraints on 3DMM parameters and landmarks, thus significantly restricts the search space and rules out implausible solutions (Figure 1). 3DI is not a…